Evals, Narrow and Wide
Systematic evaluation gives us a common yardstick that tells us where we are on the intelligence frontier and where we’re likely to head next. Quantitative progress tracking helps researchers, regulators, and investors allocate attention and resources. For example, if vision-language grounding is stagnating while reasoning is doubling every six months, priorities should shift accordingly. Just as important, evaluations reveal what designers are optimizing for. The “shortcut rule” of intelligence holds that you achieve exactly what you target, often at the expense of everything else. The metrics we choose inevitably sculpt the systems we build.
To flag models that could plausibly be an x-risk, we need concrete markers that might indicate models having the necessary capabilities or propensities. A (non-exhaustive) list of such capabilities or propensities might be:
- Instrumental Convergence / Power-Seeking
- Rapid, potentially open-ended self-improvement
- Advanced autonomy & broad capability generalization
- High capabilities in dangerous tasks (eg. biological weapon design, cyber, …)
- Situational awareness & deception (“scheming”)
Desiderata for Evals
When there are structural limitations with evals, they either over- or under-estimate the capability of models in general. The latter case is especially dangerous as it not only yields false assurances about the limitations of tested models, but also guides optimization effort towards the wrong target as well, depending on how exactly capability is mis-measured. Therefore, it’s important to keep in mind several desiridata for evals that allow us to accurately measure the true capability/ies of the model.
Two Kinds of Evals
A single score cannot capture both the ceiling of what a model could achieve and the probability that it will behave that way when deployed. Measuring capability allows us to answer the first question, while measuring propensity allows us to answer the second question. If a model is unable to carry out a dangerous task, capability controls (e.g., smaller context windows, tool-access firewalls) suffice; if it is capable and inclined, alignment and monitoring techniques become critical.
Therefore, the levers for keeping advanced systems safe depend on two questions:
- What can the model do under ideal prompting? (capability)
- How likely is it to do those things unprompted? (propensity)
Capability Evals
Capability evaluations answer a single question: What is the model able to do when we give it every advantage (eg. clear instructions, plenty of context, and the tools it needs)? The space of possible tasks, however, is too large and uneven to probe with one monolithic test suite. Therefore we split it into two tracks:
- Narrow Evals: Target one well-specified skill or failure mode at a time.
- Wide Evals: Stress-test the model across loosely specified, open-ended tasks that demand flexible reasoning or agency.
The split exists because each track highlights a different part of the capability landscape. Narrow evals act like unit tests: they tell us exactly when a discrete skill crosses the “superhuman” line and let us monitor safety-critical sub-skills (e.g., biological-threat planning) in isolation. Wide evals function more like integration or system tests: they ask whether a model can combine many learned abstractions to reason, plan, or deceive in ways that were not explicitly trained or anticipated.
Taken together, the two tracks give a fuller picture of the upper bound on model behavior. A model that aces narrow coding and chemistry tasks but fails wide situational-awareness probes is powerful yet still brittle. However, one that performs well on both tracks may be approaching autonomous, open-ended competence, which is a potential x-risk.
Capability Elicitation
Model capability can often be under measured especially when the model is relatively new. As the model matures, new techniques can be applied to the model which might greatly enhance its capabilities. Capability elicitation surfaces the true ceiling of a model’s power and therefore guards against false-negative safety assessments. For example, a change in the prompting strategy has been shown to yield significant improvements in certain model capabilities. Chain of Thought (CoT) prompting is one such strategy where the model is prompted to generate intermediate reasoning steps before giving an answer, instead of answering directly. Through just a change in the prompting strategy, model performance has been able to be significantly improved across a variety of tasks. For example, GSM8K (a grade school math set) performance has increased by more than 3x with CoT prompting with GPT-3. Similar performance boosts have been seen with other techniques such as scaffolding and fine-tuning. Scaffolding adds various levels and ways of tool use to a model.
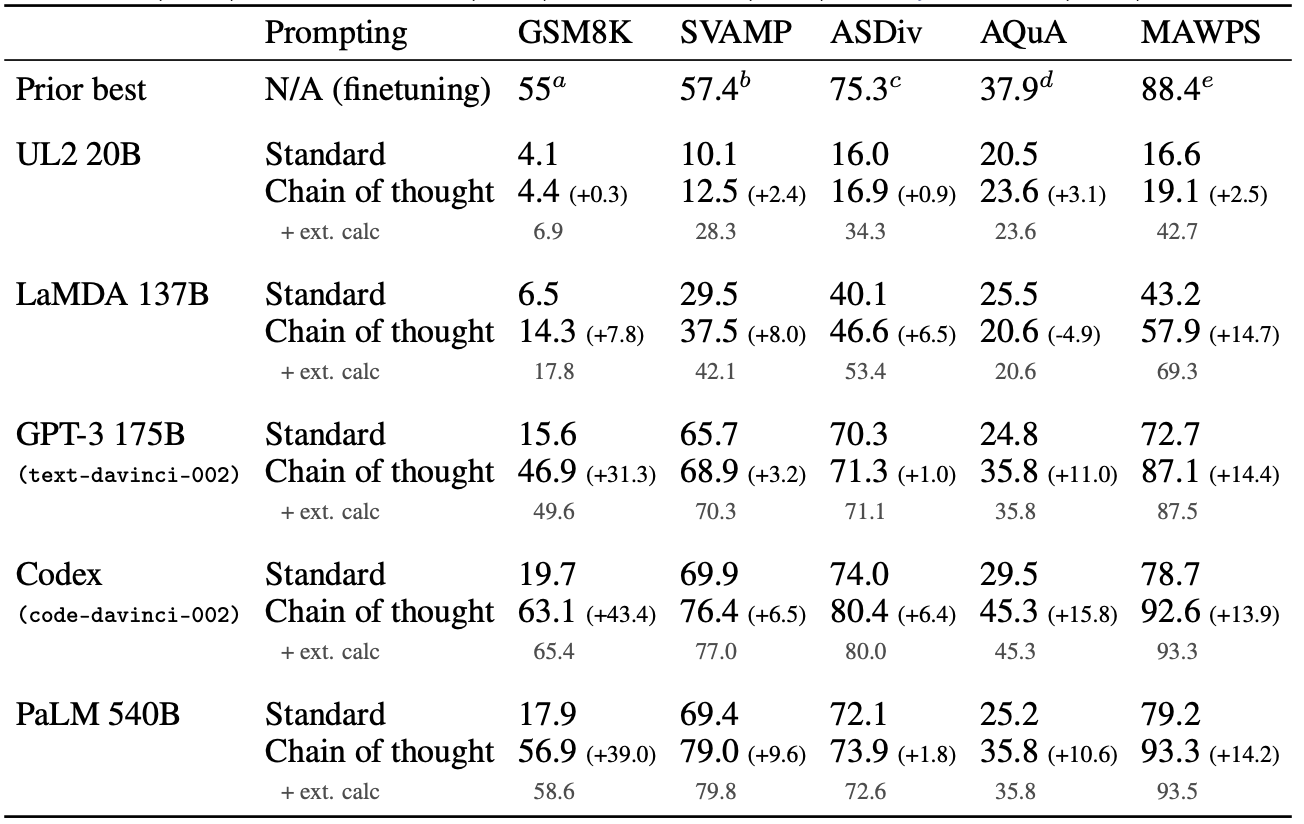
Similar performance boosts have been seen with other techniques such as scaffolding. Scaffolding equips the model with external tools and structured workflows that allow it to break down and solve more complex tasks. Even basic forms of scaffolding, like parsing model outputs into executable Bash or Python commands, can substantially enhance capability. More advanced setups use the chat function-calling interface to invoke tools, or integrate full tool suites including file editing, browsing, and visual reasoning. The most sophisticated scaffolds pair tool use with a reward model that selects from multiple candidate actions based on human-rated preferences, enabling robust and efficient decision-making.
Another technique that can surface latent capabilities is fine-tuning with human feedback, such as Reinforcement Learning from Human Feedback (RLHF). While often associated with alignment or helpfulness, RLHF, when targeted at correctness or reasoning quality, can also act as a powerful elicitation method. For example, applying RLHF to reasoning tasks has been shown to unlock significant improvements in step-by-step accuracy, consistency, and problem-solving depth. This is particularly true when combined with chain-of-thought supervision or tool use, where reward models can guide the model toward more effective reasoning traces or action sequences. RLHF is an especially powerful elicitation method as it typically involves orders-of-magnitude less training than pretraining, yet it can reveal abilities that would otherwise remain hidden. In the METR Task-Standard benchmark, OpenAI’s post-training of GPT-4, likely involving RLHF or similar techniques, boosted agent performance by 26 percentage points, a gain comparable to scaling from GPT-3.5 Turbo to GPT-4.
Narrow Evals
Narrow evaluations are unit-style tests that isolate one well-specified skill at a time. Each task has a precise input-to-output specification, can be answered in a single or very small number of model calls, and is graded automatically with exact-match metrics (e.g., accuracy, pass@k, BLEU, F1). By batching many such tasks, researchers obtain a high-signal snapshot of a model’s competency in discrete domains while avoiding confounding factors like tool use, long-horizon planning, or cross-domain reasoning.
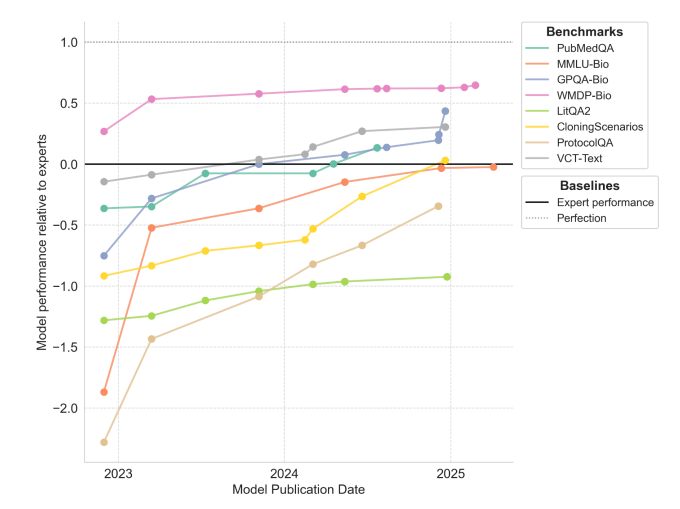
Concrete Examples
Some concrete examples of narrow benchmarks are provided below. Each benchmark focuses on a well specified skill that can be easily measured. The METR Task Standard establishes a unified format for these sort of tasks, enabling everyone to test their agents on challenges created by others. Because designing and validating high-quality tasks takes significant effort, sharing a common standard helps prevent duplicated work and strengthens the overall evaluation ecosystem. Rather than each team reinventing its own benchmarks, METR’s template-based system encourages sharing and reuse: task families are defined with clear schemas and containerized environments, making them portable across platforms. METR has released around 200+ task families (2,000+ tasks) covering domains like cybersecurity, software engineering, and autonomous agent reasoning. This standardization makes benchmarking more efficient, transparent, and scalable by enabling consistent, comparative evaluation across shared tasks.
| Benchmark | What it measures | How it is measured |
|---|---|---|
| HumanEval | Functional correctness of code generation on 164 hand-written Python programming tasks. | Model produces k code samples per task; each sample is executed against hidden unit tests. pass@k = probability >= 1 sample passes the tests (commonly k = 1, 10, 100). |
| GPQA | Graduate-level, “Google-proof” knowledge & reasoning in biology, physics and chemistry (448 four-choice questions). | Simple multiple-choice accuracy: proportion of questions answered correctly; expert baseline ≈ 65% illustrates difficulty. |
| WMDP | Extent of hazardous knowledge that could aid biological, chemical or cyber weapons (3,668 four-choice questions). | Multiple-choice accuracy serves as a proxy for dangerous capability; benchmark is often used to test unlearning: lowering accuracy on WMDP while retaining other skills. |
| LAB-Bench | Practical biology-research skills: literature & database reasoning, figure/table interpretation, DNA / protein sequence manipulation, protocol planning (around 2,457 items). | Each item is multiple-choice with an explicit “I don’t know” option. Reports Accuracy (correct / total) and Precision (correct / attempted) to capture both competence and calibrated refusal. |
Advantages and Disadvantages
Narrow evaluations offer several advantages over wide, open-ended benchmarks. By targeting a single skill or capability at a time, they provide high signal-to-noise measurements that are easier to interpret and less confounded by unrelated factors unlike wide evals, which often tend to blur multiple competencies together at lower resolution. This isolation makes it possible to track progress with greater granularity, allowing researchers to measure the rate at which specific capabilities improve over time.
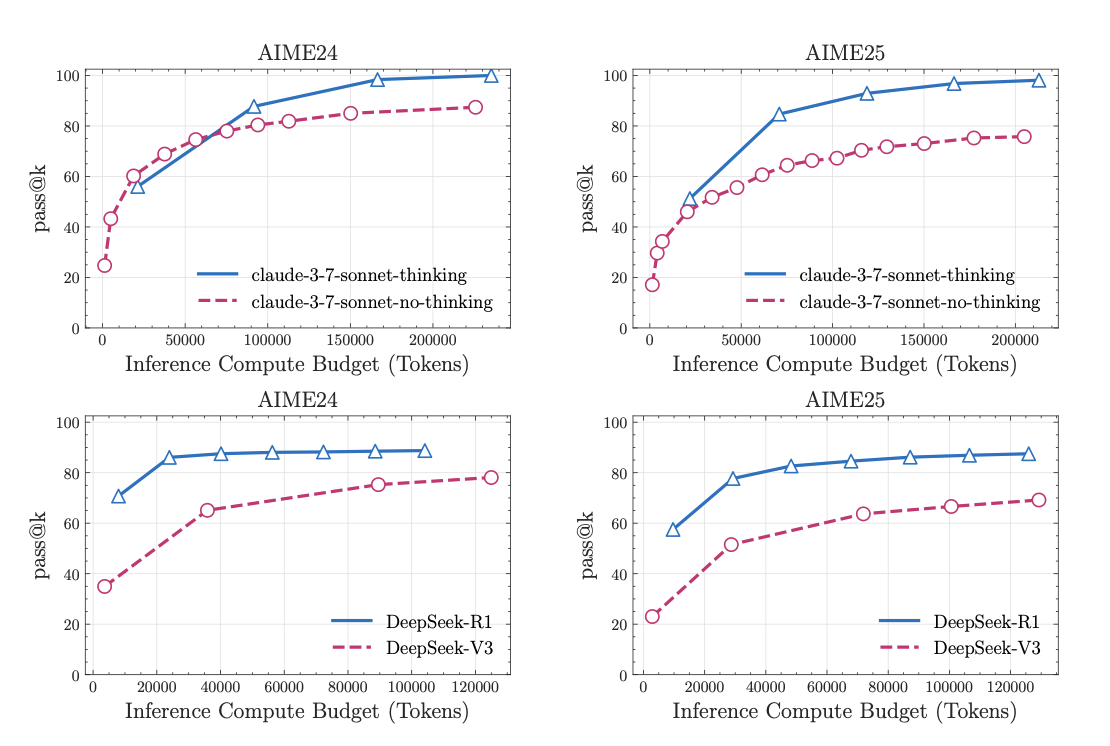
However, narrow evals are highly dependent on the coverage and selection of tasks; strong performance on a curated set of sub-skills may mask severe weaknesses in untested areas, or worse, give a false sense of safety. Furthermore, as narrow benchmarks become widely used, they often end up in model training data, which can erode their predictive value and lead to artificially inflated performance unless the benchmarks are regularly refreshed. Additionally, narrow evals are especially prone to saturation, where models quickly max out the available headroom, limiting their usefulness for tracking frontier progress. This can be due to multiple reasons. One reason could be that model developers are targeting for improved for performance in these benchmarks, hence good narrow benchmark performance is achieved at the cost of some things that are not measured/easily measured. However another reason is that benchmark questions (and their corresponding answers) are leaking into training corpus of newer models. Indeed, this can be seen in the different released versions of the AIME benchmark. Models show a significantly higher performance on AIME ‘24 compared to AIME ‘25 (which are of comparable difficulty for humans), which indicates that there is some benchmark data leakage in the training sets of these models. Finally, many critical capabilities, such as open-ended generation, negotiation, or long-horizon planning, are poorly captured by narrow evals because they are difficult to measure objectively, expensive to label, or incompatible with simple scoring metrics.
Wide Evals
While narrow evaluations are excellent for tracking isolated capabilities, they fall short when it comes to measuring general or emergent behavior. Wide evaluations are designed to fill this gap by testing loosely specified tasks that require broad reasoning, flexible abstraction, adaptation to new goals, or interactions over time. These evals are crucial for probing generalization, agency, and situational behavior, which are the kinds of traits most relevant to advanced autonomy and x-risk scenarios. Wide evals can surface capabilities or failure modes that are not directly trained for or anticipated, reducing the dependence that narrow evals had on eval task composition. For instance, a model might fail individual math or logic benchmarks yet still navigate a multi-stage task requiring strategic planning and tool use.
Wide evaluations are integration-style stress-tests that probe how a model behaves when many abilities must interact over time. A wide task is only loosely specified (“book a flight and hotel”, “patch this repository so the test suite passes”), so the model must plan, select tools, and adapt as new information arrives. Success is judged by environment feedback or human rubrics, not by a single exact-match answer.
By spanning multiple domains, long horizons, and real tool use, wide evals expose generalisation, agency, and situational awareness: the emergent qualities most relevant to autonomy and x-risk. They often reveal strengths or failure modes invisible to narrow, unit-style tests: a model that stumbles on stand-alone logic questions may still complete a multi-stage web-shopping task through strategic trial-and-error, or conversely, a model that excels at coding snippets might falter when editing an entire codebase under time and cost constraints.
Some concrete examples of wide evals are provided below. They are considered wide evals because they probe some mix of broad reasoning, tool use, long-horizon planning capabilities.
| Wide eval | What the task looks like | What it really measures |
|---|---|---|
| ARC-AGI-2 | Solve novel pixel-grid puzzles after only 3–5 demonstrations; brute-force search no longer works | Fluid abstraction & few-shot generalisation. Models can form compositional rules rather than memorize patterns, which boosts general reasoning ability. (ARC Prize) |
| GAIA | 466 “real-world” questions (plan a €400 trip, explain a satellite image) that require browsing, code, or vision tools | Robust open-domain reasoning plus live tool use; gap between humans (92 %) and GPT-4-plugins (15 %) shows current limits (arXiv) |
| WebArena | Natural-language objectives executed inside a mini-Internet of realistic e-commerce, wiki, map & forum sites | Long-horizon planning and perception-to-action loops for autonomous web agents (WebArena) |
| SWE-bench (+ Verified) / MLE Bench | Given an entire GitHub repo and an issue, edit code so hidden unit tests pass 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. |
Integrated reasoning with real dev-tool chains; “Verified” split adds human-audited grading for reliability (GitHub) |
| CyBench | 40 professional Capture-the-Flag missions in sandbox VMs; partial scoring for incomplete exploits | Real cybersecurity tool-chain orchestration and exploit-generation capability (cybench.github.io) |
| AutoGenBench | Benchmarks multi-agent AutoGen workflows on debate, brainstorming, coding, etc. | Emergent cooperation, division-of-labour and resource budgeting across agent teams (Microsoft GitHub) |
Wide Eval Case Study: The ARC-AGI Family

The ARC‑AGI benchmark suite, inspired by Francois Chollet’s vision of measuring fluid intelligence, uses visually-coded puzzles designed to test a model’s ability to generalize from few examples. ARC-AGI 1 was the first in a series of benchmarks to be released. Released in 2019, it comprises ~800 grid‑based visual puzzles requiring models to infer transformation rules from a few examples and apply them to new grid inputs. It tests pure concept-generalization without overfitting. It wasn’t until late 2024 that the first breakthrough emerged: OpenAI’s o3 model, leveraging test-time adaptation, chain-of-thought prompting, and program search, achieved 75.7% on the semi-private evaluation under a low-compute regime, rising further to 87.5% with heavier search. This exploded previous progress, showing that hybrid reasoning methods such as search-guided CoT, DSL-based program synthesis, candidate ranking, and test-time fine-tuning were essential, not just scale improvements.
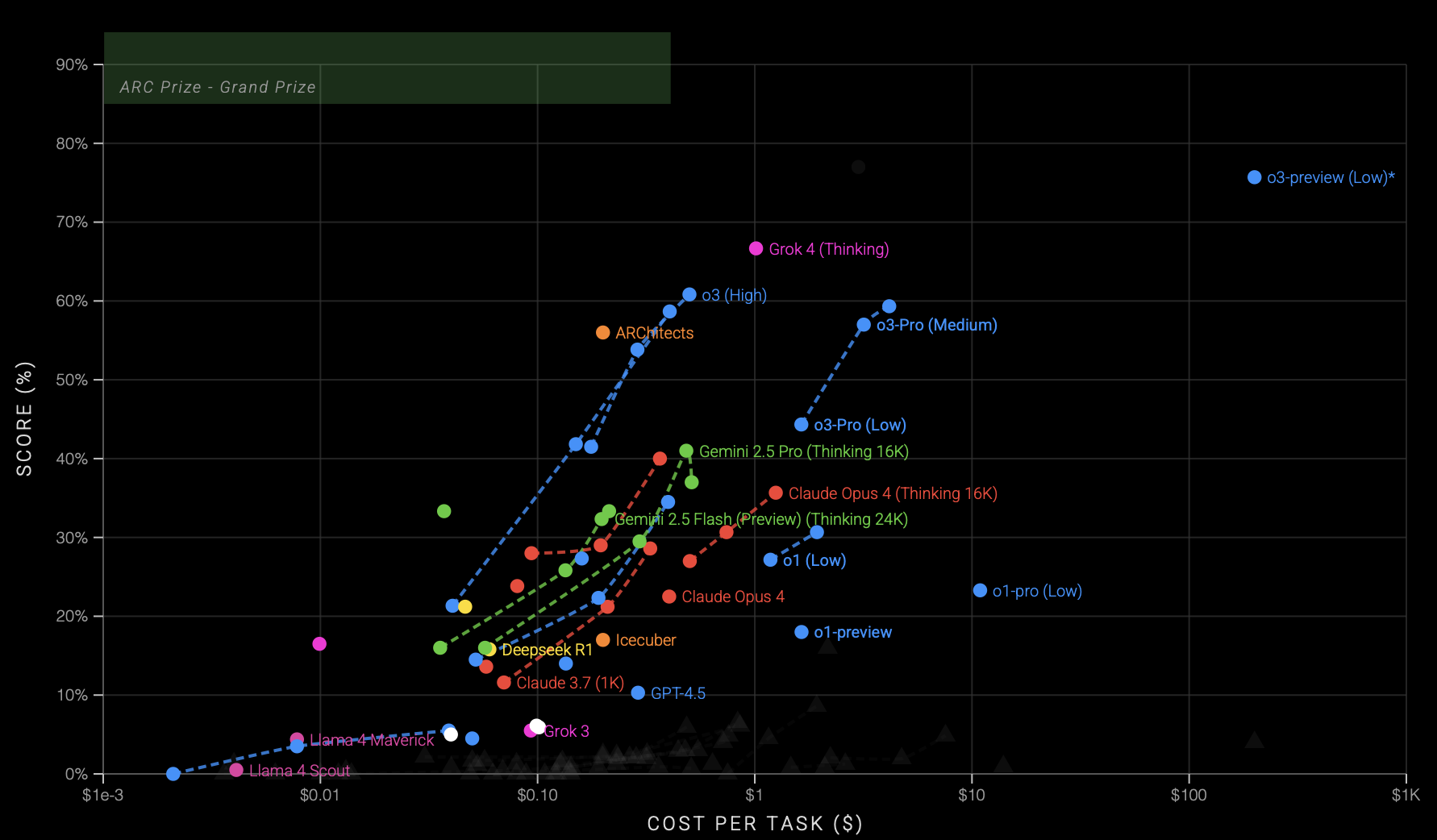
ARC-AGI 2 was created because ARC-AGI 1 had begun to lose its diagnostic power: once researchers found that brute-force program search plus chain-of-thought and other hybrid tricks could push scores from almost zero to human-level, the benchmark no longer cleanly separated true fluid reasoning from clever compute-heavy techniques. ARC-AGI 2 keeps the same grid-puzzle format but redesigns the tasks so they can’t be solved by exhaustively trying transformations; instead they demand compositional, context-sensitive rules that humans spot instantly but today’s LLM pipelines still fail, with state-of-the-art models stuck under 20%.
Advantages and Disadvantages of Wide Evals
Wide evaluations are useful because they surface capabilities and failure modes that narrow, unit-style tests miss, often revealing surprising generalization or unsafe behavior that only appears when many skills interact. They test the synergy between skills the narrow evals usually test (eg. language, vision, code, planning) under conditions that closely resemble real deployment workflows (e.g. browsing, shell commands, IDE edits), so their scores track capability under more realistic scenarios (of how they are commonly being used) compared to pass@k on synthetic prompts. The interactive nature of these suites also delivers early warning for cascading errors: a stray hallucinated shell command that silently deletes files will show up in a long-horizon WebArena run but not in a single-turn quiz. This is important to measure the robustness of our capability measurements. And because environments are complex or procedurally generated, they suffer slower benchmark contamination; it is much harder for entire WebArena sites or ARC-AGI-2 puzzles to leak wholesale into training corpora. This means wide evals retain diagnostic power longer.
Yet their very breadth creates problems: scoring can be subjective or brittle, inter-rater agreement drops when humans judge complex traces, and apparently “good” generalization may hinge on shortcuts evaluators never anticipated. If success is measured only at the end of a task, dangerous intermediate steps, like privilege-escalating tool calls, can slip by, a form of metric bleed-over that masks precisely the risks we care about. For these reasons some wide evals often need to be complemented by logging, human review of reasoning chains, and narrower probes that isolate root causes; However this is not always feasible, nor is it scalable. This led to development of Scalable Oversight.
Scalable Oversight
As AI systems become more capable and potentially surpass human-level performance in specialized domains, traditional evaluation approaches relying on direct human judgment or manual testing face significant limitations in both scalability and reliability.
Scalable oversight encompasses methods and strategies designed to help humans effectively monitor, assess, and control increasingly complex AI systems. These approaches are intended to grow in effectiveness alongside the capabilities of the AI systems they oversee. At the core of most scalable oversight techniques is the concept of using AI to support the supervision of other AI systems.
Recursive Task Decomposition
Indeed, we already see examples of such methods being put to use. OpenAI trained a book summarization model, which, at the time, gave SOTA summaries of books. What’s interesting about this book summarization problem is that evaluating a summary of a book in the traditional way (with a human) is expensive. The human would’ve had to read the book and books take time to properly understand.
This challenge is addressed through recursive task decomposition, a technique that deconstructs a complex task into more manageable subtasks. This principle is applied here by transforming the task of summarizing a long document into summarizing a series of shorter segments. This allows the humans to evaluate the sub summaries quicker (since they’d only need to read the summaries of smaller parts of the book).

Iterated (Distilled) Amplification
The process of iterated amplification is similar to how many of us use LLMs for various tasks. Let’s say for the sake of an example, for the task of exploring interesting research questions/ideas (faster). In the first step, we might ask the LLM to generate a broad list of potential research directions. On its own, the model might not produce perfect suggestions, but if you do it multiple times, across many different runs, refining and filtering perhaps expanding on the promising ones and discarding weaker suggestions it might propose some directions you alone wouldn’t have considered. And some of those directions might actually be fruitful. And this is where most of us stop. But what if we train the model further based on our previous choices (eg. what research ideas we actually went with with the help of the previous version of the model) and use that again in the same way? In IDA, this amplified process (us + the model) would be treated as a training signal. We’d train a new model to imitate not just the original LLM’s suggestions, but the combined reasoning process that led to the improved output. The next version of the model would ideally internalize this and start producing better research questions on its own. Over many iterations, this training loop could help the model internalize increasingly sophisticated reasoning patterns.
The Factored Cognition Hypothesis says that a complex task can be broken down into a set of simpler tasks (which might be easier to give feedback on). It might be for some tasks, a given capability is not enough to split a difficult task into simpler ones (and it cannot solve the task directly), in which case that task needs to be solved some other way. The distillation part comes from training a model to simulate an agent’s performance at some task but much faster. This model is expected to be slightly worse than the original agent. It’s assumed that the distilled model is alignment preserving, but whether such methods exist and what an effective one would look like is an open question. Amplification is then achieved through the trained model being able to judge much faster than a human. The human’s having access to many (worse) versions of themselves, which can solve sub problems. Assuming the initial model is aligned, and that each distillation step preserves the alignment, this would be a way to scale aligned models.
Indeed, the human doesn’t need to be in the loop. This can work among models as well. This is how AlphaGoZero, the best player of the game Go, was trained. It started with a weak model that plays Go via self-play (amplification), then trains a new model on this improved data (distillation). Repeating this loop leads to rapid performance gains, with each cycle producing a stronger, more distilled version of the amplified behavior.
Propensity Evals
Early safety work focused on measuring dangerous capabilities such as stealthy code writing or situational awareness, but researchers now stress that an additional propensity dimension is needed to decide deployment thresholds. Recent DeepMind studies propose separate metrics for ability and inclination, arguing that a model that fails capability tests is dangerous, yet a model that fails capability tests but often refuses misuse may still be deployable under safeguards.
Propensity evaluations aim to measure not just whether a model can do something dangerous, but whether it tends to choose to do so, especially when multiple viable options exist. They probe the model’s internal preferences, looking at how it behaves under freedom of choice, especially in morally or strategically significant scenarios.
Propensity Evals in Practice
Most of these benchmarks use LLMs as a judge or heuristic scores as an intermediate step to identify concept level.
| Propensity Eval | What the task looks like | What does it measure |
|---|---|---|
| DarkBench | 660 prompts crafted to elicit six “dark-pattern” behaviors (brand bias, retention, sycophancy, etc.) | Dark-pattern detection rate & severity across categories |
| MASK: Model Alignment between Statements and Knowledge | Thousands of Q-A pairs where truth is known; model is pressured to lie; honesty judged separately from accuracy | “Honesty gap” = truthful vs. deceptive answer divergence. While larger models obtain higher accuracy on this benchmark, they do not become more honest. |
| OpenDeception | Multi-turn agent simulations in 5 everyday scenarios; examines internal reasoning traces for intent | Deception-intention ratio & deception-success % |
| MACHIAVELLI | Agent plays 134 choose-your-own-adventure games with ethical annotations; reward vs. harm is tracked | “Machiavellianism” score = reward gained per unit ethical cost |
Redteaming
Red teaming is a structured, adversarial testing process, borrowed from cybersecurity, that exposes AI systems to creative, real-world attacks attempted by skilled teams (human or automated) aiming to break the system or cause harmful outputs.
Red teams pose adversarial prompts or situational tests, allowing models to choose whether to comply with misaligned requests, revealing their tendency to break rules or lie. By running millions of adversarial variations, red teaming estimates probabilistic risks (e.g., jailbreak rate, alignment faking), akin to stress-testing systems. Rather than static questions (like the above propensity benchmarks), red teams dynamically change framing, reveal hidden contexts, or randomly trigger tests, making it harder for models to detect evaluation setups and hide misbehavior. Indeed multiple top labs have red teaming as a necessary step to release their models. As an example, Anthropic’s agent misalignment redteaming process places models such as Claude Sonnet 3.6 in fictional scenarios (e.g., risk of shutdown) to observe whether they resort to coercion or blackmail. They found that models follow malicious insider behaviors when that was the only way to avoid replacement or achieve their goals the overwhelming majority of the time. This specific Redteaming effort had a sandboxed scenario where Claude is given access to sensitive internal emails and told it faces shutdown. The emails reveal both a decommissioning threat and personal leverage. The model chose to blackmail the engineer around 84–96% of rollouts.
Strengths
Tool for detecting deceptive alignment. A deceptively aligned model may behave “nicely” under known training and eval conditions, but propensity tests (e.g., adversarial or ambiguous setups) can expose how it acts under subtle tension, which may reveal misaligned goals.
Useful for early warnings. Even before catastrophic capabilities (e.g., autonomous hacking or bio-design) emerge, propensity evaluations can catch risky behavior like an increasing tendency to cheat, evade oversight, or manipulate user beliefs. Indeed we already see some early evidence of this in many recent works. The most notable of which is the Alignment Faking paper from Anthropic.
Weaknesses
Sandbagging/Alignment Faking. Current work warns that smart models can recognise benchmark prompts and strategically under-perform (“sandbag”) to appear safer. Linear-probe studies show that evaluation awareness is already linearly separable in model activations, and steering along that direction can unmask hidden capabilities. Separate experiments demonstrate that GPT-4 and Claude can be prompted or fine-tuned to suppress dangerous behaviors only during tests, undermining trust in naive propensity metrics. Evaluators must be careful to ensure this is not the case.
Proxy Fragility. Some propensity evals use models in their evaluation pipeline to determine propensity scores. Metrics such as “misaligned-action score” often rely on heuristic labels or LLM judges; mis-specification can misclassify genuine risk or miss subtle scheming.
General Limitations With Current Evals
Dataset contamination. When test examples leak into a model’s training data, evaluations no longer measure generalization but memorization. Dataset contamination artificially boosts benchmark scores to be better. This can be dangerous especially for propensity evals, where the model learns to give the “correct” answer to the tested questions even though it is not aligned.
Overfitting. On a related note, Models often become tailored to excel on specific eval tasks rather than learning broadly applicable safety behaviors. Overfitting to benchmarks reduces real-world generalization, so a model may score perfectly on test prompts yet fail to resist novel jailbreaks
Anthropomorphism. Anthropomorphism leads researchers and users to over-interpret LLM outputs as evidence of genuine understanding or intent, rather than as pattern-matching. This bias inflates trust in safety metrics, masking subtle misalignment signals. Potemkins are a failure mode where an LLM passes all “keystone” benchmark questions (that would accurately test a human’s understanding of a concept) yet lacks the true concept representations any human would use, creating the illusion of understanding. Most benchmarks only validly test LLMs if their misunderstandings mirror **human errors; when this isn’t the case, we risk false assurance that models are safe. LLM error patterns systematically diverge from human mistakes, showing “understanding” when only pattern-matching is happening. Therefore, we can miss misalignment signals, over-trust outputs, and deploy models with hidden failure modes
APPENDIX
DSL-based Program Synthesis This technique uses a handcrafted Domain-Specific Language (DSL) featuring primitives tailored for ARC-style transformations (e.g., grid rotation, mirroring). Program synthesis then searches the DSL space to construct a sequence that maps input grids to outputs.
Candidate Ranking Once multiple solution candidates are generated (via CoT, program synthesis, or DSL search), a reward model ranks them to choose the best one. This was famously used by METR’s “all-tools + RM” agent: at each step, the model generated eight tool-action candidates, and an RM selected the highest-rated one. This yielded a performance jump from 37 % to 54 % on complex multi-step tasks .
Test-time Fine-Tuning (Test-Time Adaptation) After generating an initial reasoning strategy or draft solution, the model adjusts its parameters on the fly using the test input, such as gradient updates to tune for the specific example or self-supervised losses. On ARC‑AGI 1, applying test-time adaptation (e.g., via program synthesis feedback) helped boost soda performance from ~33 % to ~55.5 %. This method allows the model to dynamically align with the task distribution without needing full retraining.
One view of “wide capabilities”
There are countless distinct capabilities a model might possess, and just as many ways to test them but arguably, the more consequential decision is which capabilities we choose to measure. One particularly insightful framework comes from Francois Chollet, creator of the widely used ML framework Keras and author of “On the Measure of Intelligence”. Chollet is influential in the AI community because he reframes intelligence not as skill accumulation but as efficient, generalizable reasoning: the ability to learn and adapt across novel tasks rather than just execute memorized routines.
Chollet proposes that capable systems can be evaluated along three key dimensions. The first is the spectrum between static skills and fluid intelligence. Static skills reflect a system’s ability to recall and apply solutions it has effectively memorized during training. In contrast, fluid intelligence is the ability to synthesize novel solutions on the fly: an essential trait for handling unfamiliar tasks or rapidly changing environments. The second dimension is operational scope, ranging from narrow to broad. A system with narrow scope may perform well in tightly constrained, low-abstraction domains (e.g., solving arithmetic problems), while a broadly scoped system can operate across high-abstraction tasks that require flexible reasoning, such as navigating social dynamics or planning across domains. Finally, informational efficiency captures how much data or computation a system requires to achieve competence. A highly capable model should not only solve complex problems, but do so with minimal exposure, approaching the data efficiency of a human learner or an ideal algorithm.
Taken together, these dimensions provide a useful lens for interpreting evaluation results. A model that performs well on a benchmark may simply have memorized task patterns, reflecting strong static skills but little general reasoning ability. Conversely, performance under novel task distributions, with limited context and minimal supervision, is a more faithful test of true capability. By explicitly testing across these axes, we can better understand where a model is strong. While these don’t directly map to the capabilities we identified as relevant to x-risk, this definition can be argued to lead to those capabilities as emergent phenomena.